Es ist geschafft. Die Klausurenphase, die mich die letzten paar Wochen in ihrem Griff hielt, ist gelaufen. Und wenn ich sie kurz rekapitulieren darf, so würde ich sagen, dass sie für mich lief, wie die letzte Fußball-WM…
…für Brasilien.
Sprich: Der Einstieg war wunderbar, die ersten paar Spiele liefen hervorragend und die Hoffnungen stiegen hoch, aber gegen Ende lief es dann doch eher desaströs. Naja, dafür gibt’s ja die Möglichkeit, Klausuren zu wiederholen.
Aber genug von mir, ihr seid ja nicht hier, um weiter mein persönliches Geplauder ertragen zu müssen, sondern um mehr über Gentechnik zu erfahren. Also setzen wir direkt dort an, wo wir beim letzten Text aufgehört haben. Nämlich bei dem Weg der RNA, die sich gerade vom eigentlichen DNA-Strang getrennt hat. Wir sprechen hierbei von einer sogenannten „unreifen RNA“ oder auch „prä-mRNA“. Sie hat nichts mehr mit der DNA zu tun, ist aber auch noch nicht ganz bereit, ein Protein zu werden.
Um endlich ein Protein herzustellen, müssen wir die RNA aus dem Zellkern schaffen. Vorher aber, muss die RNA für ihren Weg präpariert werden. Diese Präparation ist auch als RNA-Prozessierung bekannt. An Ende dieses Prozesses wird dann aus der „unreifen RNA“ die „reife RNA“, die man auch als mRNA bezeichnet.
Im ersten Schritt, dem sogenannten „Capping“, wird am 5‘-Ende der RNA ein Guanin-Nukleotid angebracht. Diese „Kappe“ dient insbesondere als Erkennungsmerkmal für die Zelle, dass hier ein zukünftiges Gen am Wandern ist.
Im nächsten Schritt, der sogenannten Polyadenylierung, wird der RNA ein Schwanz angehängt. Eine Kette von bis zu 250 Adenin-Nukleotiden wird am 3‘-Ende befestigt. Dieser Schwanz, genau wie die Kappe, bewahrt die RNA davor, innerhalb der Zelle versehentlich abgebaut zu werden. Im Laufe der Zeit verkürzt sich dieser Schwanz allerdings und kontrolliert somit die Lebensdauer der RNA.
Der nächste Schritt ist besonders interessant. Das sogenannte Editing. Hier erleben wir natürliche Gentechnik. Während des Editings werden nämlich Basen der RNA verändert. Ziel des Ganzen ist es, für eine größere Vielfalt an Proteinen zu sorgen, die letztendlich aus der RNA entstehen werden. Ein schönes Beispiel dafür findet sich im Dickdarm und in der Leber. An beiden Orten findet man ein Protein namens Apolipoprotein. Es ist in erster Linie ein Strukturprotein und für den Fettstoffwechsel zuständig. In beiden Organen findet sich haargenau dasselbe Gen, das dafür verantwortlich ist, dieses Protein herzustellen. Mit einer Ausnahme. Passenderweise ist an Position 6.666 eine Base der Sequenz verändert. Dies führt zu einem Unterschied in der Herstellung des Proteins. Interessanterweise ist es im Dickdarm um ganze 2.384 Aminosäuren kürzer, als das Protein in der Leber. Die unterschiedliche Länge basiert auf der veränderten Base, die dafür verantwortlich ist, dass die Translation (auf die wir gleich zu sprechen kommen) beim Protein im Dickdarm früher beendet wird, als bei dem in der Leber. Hin und wieder werden Gene erst durch diese Form des Editing überhaupt translationsfähig gemacht.
Nun folgt der finale Schritt der RNA-Prozessierung. Das sogenannte Splicing. Beim Splicing wird die mRNA zurechtgestutzt. Denn nicht alle Basen aus der RNA werden am Ende auch zu Proteinen umgewandelt. Die Stellen, die herausgeschnitten werden, nennt man Intron. Exon werden die Basen genannt, die nach dem Splicing übrig bleiben und die fertige mRNA bilden. Diese mRNA, oder auch „reife mRNA“, wird dann am Ende auch wirklich komplett zum Protein umgewandelt.
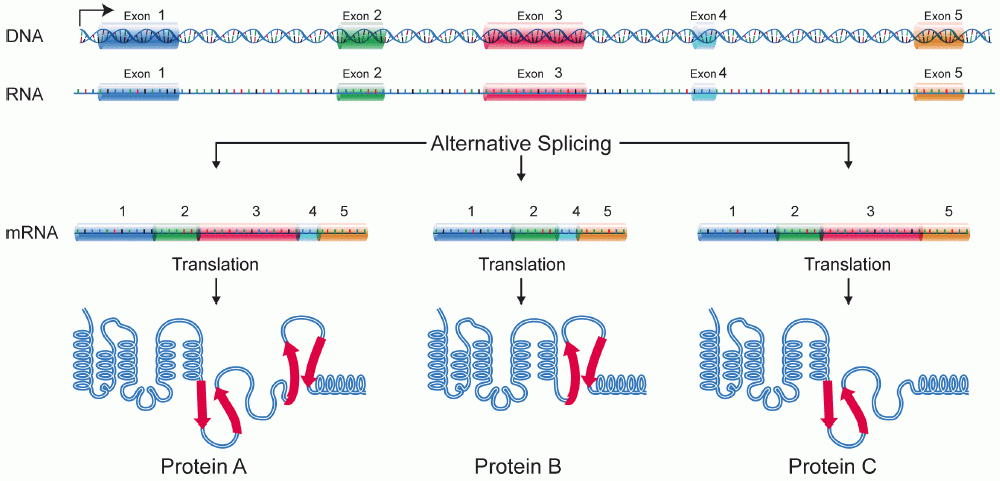
Hier hätten wir die schematische Darstellung dieser Umwandlung, mit diversen verschiedenen Proteinen, die im Verlaufe des Editing entstehen können.
Nun ist die mRNA fertig und bereit, ein Protein zu werden. Und jetzt wird es erst richtig spannend. Bis hierher drehte sich alles um die sogenannte Transkription. Die Umwandlung von DNA in mRNA. Von jetzt an reden wir über die Translation. Jetzt geht es darum, aus der mRNA auch wirklich ein Protein zu machen.
Das passiert aber nicht einfach so, dafür brauchen wir ein kleines Zellorganell, das sogenannte Ribosom. Der Vorgang im Ribosom sieht folgendermaßen aus:
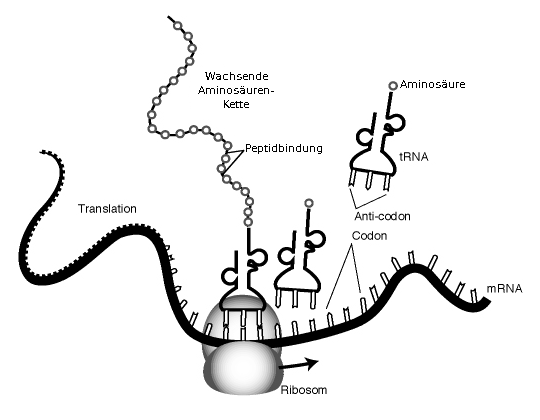
Wir beginnen im Ribosom, indem wir unseren mRNA-Stang von rechts in das Ribosom einführen. Das Ribosom hat 3 „Kammern“, die mit A, P und E (von rechts nach links) gekennzeichnet werden. In jeder Kammer halten sich zu jeder Zeit exakt 3 Basen des mRNA-Strangs auf. Diese 3 Basen bilden später jeweils exakt eine Aminosäure. Ganz einfach. 3 Basen = 1 Aminosäure. Diese 3 Basen werden auch Basentriplett, bzw. Codon genannt. Die Aminosäuren, die damit gebildet werden, werden vom Ribosom zu Aminosäureketten unterschiedlicher Länge zusammengebaut. Diese Ketten bezeichnet man dann letztendlich als Protein.
Um die Umwandlung der mRNA in Aminosäuren zu starten, muss ein ganz bestimmtes Codon vom Ribosom gelesen werden. A-U-G sind die 3 Basen, die dem Ribosom das Signal geben, die Aminosäure zu bauen. Diese 3 Basen können irgendwo auf dem Gen stehen. Egal ob am Anfang oder weiter hinten, es spielt keine Rolle. Das Ribosom fängt erst dann mit seiner Arbeit an, wenn es dieses Startsignal erhält.
Im der A-Kammer (der sogenannten Aminoacyl-Stelle) des Ribosoms passiert mit diesem Codon folgendes:
Es trifft auf ein sogenanntes Anti-Codon, oder auch tRNA. Dieses Anti-Codon enthält die komplementären Basenpaare für das Codon. In unserem Start-Codon A-U-G wären in diesem Fall also U-A-C das Anti-Codon. Und an diesem Anti-Codon hängt die erste Aminosäure. Dieses Codon-Anti-Codon-Paar wandert dann von der A-Kammer in die P-Kammer (währenddessen wandert das nächste Codon der mRNA in die A-Kammer und wird dort mit seinem Anti-Codon, also der nächsten Aminosäure ausgestattet).
In der P-Kammer (der Polypeptid-Stelle) wird die Aminosäure gelöst und mit den nun folgenden Aminosäuren zu einer langen Kette verbunden.
Das Codon wandert nun aus der P-Kammer in die E-Kammer (während das nächste Codon in die P-Kammer wandert, dort seine Aminosäure als neuestes Glied der Aminosäurenkette hinzufügt und ein weiteres Codon in der A-Kammer mit einer Aminosäure ausgestattet wird).
In dieser E-Kammer werden nun Codon und Anti-Codon wieder voneinander getrennt. Die Schritte in den einzelnen Kammern wiederholen sich nun so lange, bis der mRNA-Strang ein Stopp-Codon nachschiebt, das diesen Vorgang beendet. Ähnlich wie am Anfang des Vorgangs, kann sich das Codon irgendwo auf dem mRNA-Strang befinden. Im Gegensatz zum Start-Codon gibt es drei verschiedene Codons, die den Vorgang beenden können: U-A-A, U-A-G und U-G-A.
Für diese drei Codons gibt es kein Anti-Codon, wodurch die Aufreihung der Aminosäuren, also der Bau des Proteins beendet wird. Egal wo sich dieses Stopp-Codon auf dem Strang befindet, das Ribosom hört mit seiner Arbeit auf, sobald es auf ein Stopp-Codon trifft und zerfällt in seine Einzelteile, bis es für den nächsten mRNA-Strang gebraucht wird.
Ein Protein ist also nichts anderes, als eine Kette von Aminosäuren unterschiedlicher Länge. Bei Ketten von mehr als 100 Aminosäuren spricht man von Proteinen. Kürzere Ketten werden als Peptide bezeichnet. Am Aufbau von Proteinen sind 23 Aminosäuren beteiligt. Interessant. Dabei gibt es ja (wenn ich mich nicht verrechnet habe) eigentlich 64 Möglichkeiten, ein Codon zu bilden. Man könnte also (wenn man das Start-Codon, sowie die 3 Stopp-Codons abzieht) glauben, dass es auch 64 Aminosäuren gibt, die an der Herstellung von Proteinen beteiligt sind. Es gibt allerdings diverse Codons bei denen es keinen Unterschied macht, welche Base den Abschluss bildet. Es wird trotzdem immer dieselbe Aminosäure hergestellt. Zum Glück gibt es in der Biologie die Möglichkeit, mittels einer Grafik schnell festzustellen, welche Codons welche Aminosäure ausbilden.
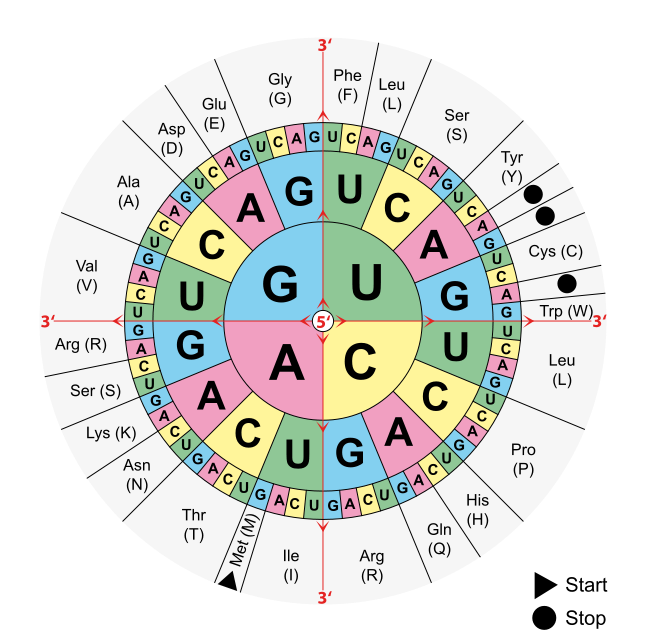
Das ist die sogenannte Code-Sonne, oder auch Gen-Sonne. Man liest sie von innen nach außen, um zur gewünschten Aminosäure zu kommen. Ein Beispiel gefällig? Nehmen wir mal… C-G-A.
Wir fangen also in der Mitte beim C an, arbeiten uns zum darunterliegenden G vor und von dort aus sehen wir etwas Interessantes. Es scheint keine Rolle zu spielen, welches der dritte Buchstabe ist. Denn sowohl C-G-A, C-G-C, C-G-U und C-G-G bilden die gleiche Aminosäure aus. ARG. Arginin. Diese Aminosäure ist in der Lage, Blutgefäße zu weiten, aber das nur am Rande.
Jede Aminosäure hat einen eigenen Buchstaben als Kürzel, der ist unter der Abkürzung zu lesen. Hin und wieder stellen komplett unterschiedliche Codons auch dieselbe Aminosäure her, so zum Beispiel A-G-C, A-G-U, sowie U-C-X (X ist hier ein Platzhalter, weil der dritte Buchstabe dort keine Rolle spielt). Sie alle bilden die Aminosäure Serin aus.
Welche Funktionen Proteine für den Körper haben ist schnell erklärt: Sie machen praktisch alles.
Um schon Mal einen kleinen Ausblick in Richtung Gentechnik und Insektenvernichtung zu geben:
In den USA wurden Maissorten gentechnisch verändert, um ein Protein herzustellen, das den sogenannten Maiswurzelbohrer vergiften soll. Dieses Protein ist für Menschen ungefährlich und soll den Einsatz von Insektiziden in der Landwirtschaft verringern.
Dummerweise war der Anteil dieses Proteins in den Maispflanzen lange Zeit zu gering, sodass nicht alle Schädlinge getötet wurden, was zur folge hatte, dass sich die überlebenden Maiswurzelbohrer – die eine Resistenz gegen dieses Protein haben – vermehren konnten und diesen Insektenschutz somit unwirksam gemacht haben.
Dazu kommen wir aber an einem anderen Punkt unserer Reihe, nämlich wenn wir über Anwendungen, Erfolge und Misserfolge der Gentechnik reden.
Wir sind erstmal am Ende unserer Grundlagen angekommen und werden im nächsten Text über den Vater der Genetik sprechen: Gregor Mendel. Wir schauen uns außerdem an, wie Vererbung abläuft.