Im Jahr 1958 wurde der Nobelpreis für Medizin oder Physiologie an drei Herren verliehen. Einer von ihnen hieß George Wells Beadle. Der andere Preisträger heißt Joshua Lederberg. Gemeinsam mit dem dritten Preisträger, Edward L. Tatum wurden sie für die Bestätigung folgender Behauptung ausgezeichnet:
„Ein Gen steuert die Produktion eines Enzyms“
Das ist ja erstmal eine ganz nette Theorie, aber was genau dahinter steckt, und welchen Einfluss dieser Nachweis auf zukünftige Forschungen hatte, klären wir jetzt und in zukünftigen Texten. Zugeben, die Tragweite dieser Entdeckung sollte jedem bewusst werden. Immerhin gab es dafür nicht nur den Nobelpreis, der Wissenschaftszweig der „GENtechnik“ trägt den Begriff heute noch im Namen.
Was ein DNA-Strang ist, wissen wir ja mittlerweile. Die Doppelhelix kann vermutlich auch jeder von uns im Schlaf aufzeichnen. Gene sind nun nichts anderes, als Ketten von Basenpaaren, die unter anderem dafür genutzt werden, Aminosäuren herzustellen.
Im letzten Text habe ich geschrieben, dass jeder unserer DNA-Stränge rund 2 Meter lang ist. Auf diesen zwei Metern befinden sich rund 3.270.000.000 Basenpaare, die 23.000 Gene ausbilden. Diese Gene, die dafür zuständig sind, Aminosäuren, also die Grundlage unserer Proteine, zu erstellen, machen allerdings nur rund vier Prozent der DNA aus. 52% des DNA-Stranges besteht aus nicht-kodierenden Regionen, die nichts mit der Proteinbiosynthese zu tun haben. Der Rest besteht zum größten Teil aus Genfragmenten diverser Viren, die irgendwann mal in unsere DNA eingedrungen sind, und bis heute ihre Überreste in selbiger gelassen haben. Für uns ist erstmal wichtig, wie Proteine entstehen. Aber eines Tages sprechen wir auch über die anderen Regionen der DNA. Bis dahin gibt’s hier ein bisschen was zum weiterlesen. Natürlich sind die Regionen nicht fein säuberlich voneinander abgegrenzt. Es gibt längere Abschnitte, die aus nicht-kodierenden Regionen bestehen, in die sich nur vereinzelt Gene gemogelt haben, dann gibt es wiederum Abschnitte, in denen mehrere Gene dicht aufeinander folgen, usw. Wie man nun rausfindet, wo ein bestimmtes Gen beginnt, klären wir später.
Gene sind also die „Blaupausen“ für Aminosäuren. Diese Aminosäuren bilden dann wiederum den Ausgangsstoff für jedes Protein und jedes Enzym; Aminosäuren helfen bei Verletzungen oder beim Wachstum des Körpers, Aminosäuren bilden schlicht und Ergreifend die Basis des Lebens.
Um aus einem Gen eine Aminosäure zu machen, muss man den betreffenden DNA-Strang, auf dem das Gen liegt, erstmal ein wenig umschreiben und ihn anschließend aus dem Zellkern schaffen. Im letzten Text über die DNA-Replikation haben wir ja gesehen, dass ein DNA-Strang in zwei Mutterstränge aufgespalten wird, an die dann jeweils ein Tochterstrang angebracht wird. Der Mutterstrang, der vom 3′-Ende zum 5′-Ende verläuft, wird benutzt, um einen RNA-Strang herzustellen, der am Ende alle Informationen enthält, die zur Herstellung von Aminosäuren notwendig sind. Der verwendete Mutterstrang heißt auch „Codogener Strang“ oder auch „Antisense Strang“.
Nun kommt ein Enzym namens RNA-Polymerase ins Spiel. Ähnlich wie die DNA-Polymerase läuft auch die RNA-Polymerase den Mutterstrang ab und bindet komplementäre Basenpaare aneinander. Der so entstandene, neue Strang, heißt RNA-Transcript. Dort gibt es allerdings ein paar Unterschiede, was die Kombination der Basenpaare angeht.
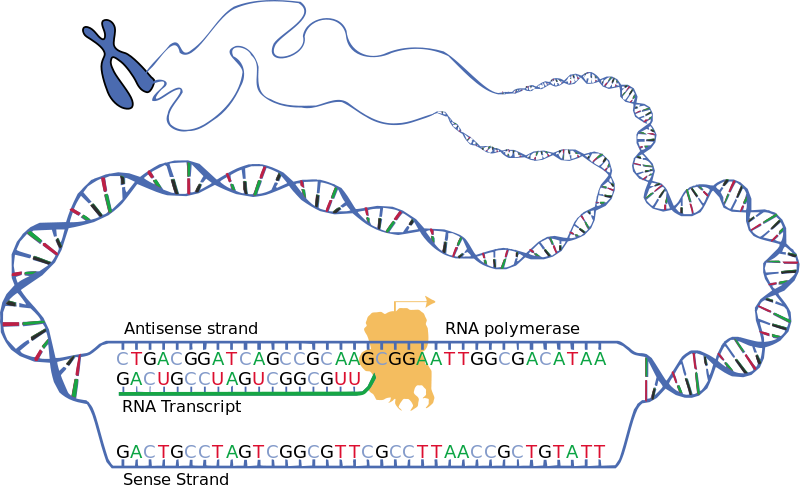
Auf diesem Bild sehen wir, dass am Mutterstrang, von links nach rechts, folgende Basen hängen:
Cytosin, Thymin, Guanin und Adenin.
Der neue Strang, das RNA-Transcript, der mit der RNA-Polymerase gebildet wurde, besitzt jetzt folgende Basen:
Guanin, Adenin, Cytosin und Uracil.
Das heißt, jedes Cytosin der Mutter, hat auf dem Transcript Guanin, jedes Guanin der Mutter hat Cytosin auf dem Transcript. Das Thymin der Mutter bekommt Adenin auf dem Transcript. Lediglich das Adenin der Mutter bekommt eine neue Base als Partner, nämlich Uracil.
Bei der RNA-Transcription verschwindet also die Base Thymin und Uracil nimmt ihren Platz ein. Und wie es auch schon bei der DNA-Polymerase der Fall ist, so muss man auch bei der RNA-Polymerase folgendes beachten: Die jeweiligen Polymerasen stellen keine Basen her! Sie „nehmen“ lediglich die Basen, die ohnehin schon im Zellkern herumschwimmen, und fügen sie jeweils passend zusammen. Dieser RNA-Strang wird auch als mRNA bezeichnet. Es bedeutet „messenger Ribonucleinacid“, und bedeutet nichts anderes, als dass dieser RNA-Strang die „Nachricht“ eines speziellen Gens mit sich trägt.
Damit die RNA-Polymerase weiß, wo ein Gen beginnt und wo es endet, gibt es eine spezielle Abfolge von Nukleotiden, die angeben, wo Gene beginnen und wo sie enden. Diese Anfangssequenz wird „Promotor“ genannt, die Endsequenz heißt „Terminator“ (und wenn ich dem Drang widerstehen kann, schlechte Wortspiele und Referenzen rauszuhauen, schafft ihr das auch. Ich glaube an euch!). Ist die RNA-Polymerase an einem solchen Terminator angekommen, heißt es „hasta la vista, baby“ (okay, ich bin gescheitert…) und das RNA-Transcript trennt sich vom DNA-Strang.
Der Prozess, der bis zu diesem Punkt abgelaufen ist, wird auch Transkription genannt. Im nächsten Text geht es dann um die Frage, wie man die RNA aus dem Zellkern bekommt, und wie aus den Genen eigentlich Aminosäuren werden.